Python有趣|數(shù)據(jù)分析三板斧

前言
天下武功中,哪個是最簡單,最實(shí)用的了?那當(dāng)然是程咬金的三板斧。傳說中,程咬金晚上睡覺,夢見一老神仙,教了他三十六式板斧,這套功夫威力極大,而且招式簡單,十分適合程咬金,但是程咬金醒來之后就只記住了三招,便有了這三板斧。就是這簡單的三板斧,幫助李世民建立大唐江山。
這個教程將以簡單,有效,實(shí)用為原則,讓大家也能簡單入門Python數(shù)據(jù)分析,學(xué)會這三板斧,讓讀者以后在學(xué)習(xí)數(shù)據(jù)分析的過程中,少走彎路。
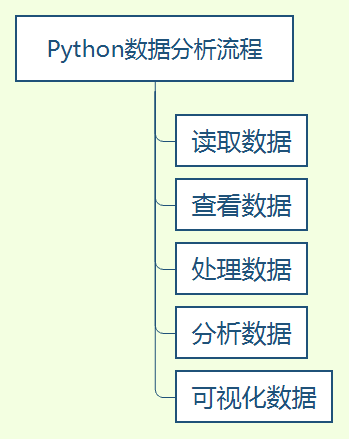
Python數(shù)據(jù)分析流程
用Python做數(shù)據(jù)分析的優(yōu)點(diǎn)就是,通過一個pandas庫就能完成整個數(shù)據(jù)分析流程。簡單的流程是,一讀二看三處理四分析五展示,skr~。如下圖所示。
PS:所有數(shù)據(jù)分析不以業(yè)務(wù)為依托,都是耍流氓~
讀取數(shù)據(jù)
這里以全球星巴克的數(shù)據(jù)為例(https://www.kaggle.com/starbucks/store-locations),首先提出問題(前文說過要以業(yè)務(wù)為基礎(chǔ),這里我們只能提前定義幾個感興趣的問題),哪些國家星巴克店鋪較多;哪些城市星巴克店鋪較多;中國星巴克店鋪分布情況。
首先通過read_csv讀取數(shù)據(jù),將文件轉(zhuǎn)換為DataFrame格式,這樣我們就可以在Python中進(jìn)行處理。當(dāng)然,pandas支持各種文件格式(read_excel,read_sql等等),做詳細(xì)系列的時候逐一講解。
- import numpy as np
- import pandas as pd
- data = pd.read_csv('directory.csv')
- data.head()
查看數(shù)據(jù)
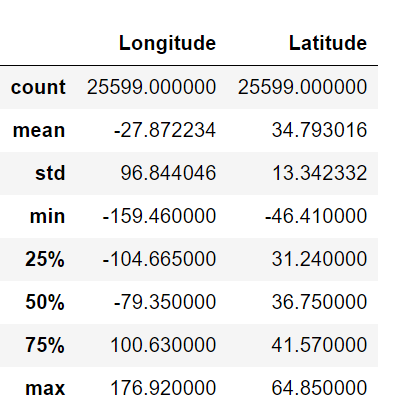
我們可以通過describe和info方法對整個數(shù)據(jù)有個大概的情況。describe用于查看數(shù)值型數(shù)據(jù)的分布情況。
- data.describe()
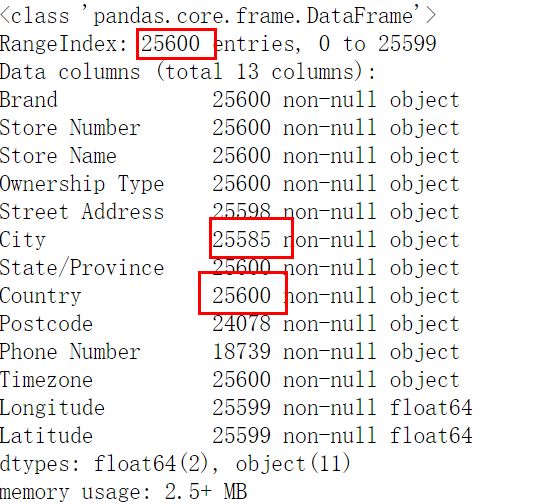
info方法用于查看各字段的數(shù)據(jù)類型,以及缺失情況,可用于后面的數(shù)據(jù)處理。這里我們根據(jù)問題,對country和city字段感興趣,然后發(fā)現(xiàn)city缺失,所以后文中需要對其處理。
- data.info()
數(shù)據(jù)處理
數(shù)據(jù)處理,其實(shí)就是我們常說的數(shù)據(jù)預(yù)處理(清洗數(shù)據(jù)),我們都知道,數(shù)據(jù)大部分情況下,是不干凈的(或者不是我們預(yù)期的),我們需要處理,清洗,常出現(xiàn)的處理任務(wù)如下:
- 缺失值處理
- 異常值處理
- 重復(fù)值處理
- 多表處理
- 數(shù)據(jù)轉(zhuǎn)換處理
這些都是需要根據(jù)實(shí)際情況來處理的。接著,我們就來處理星巴克數(shù)據(jù),首先,查看Brand字段的唯一值,發(fā)現(xiàn)除了星巴克還有其他商品(可能是同一廠商的,屌絲表示對星巴克一無所知),我們只取星巴克的數(shù)據(jù)。

之前我們用info函數(shù)可以查看缺失值,但是我們常用isnull函數(shù),這樣可以清楚看出各字段的缺失值都有多少數(shù)據(jù)。
- data.isnull().sum()
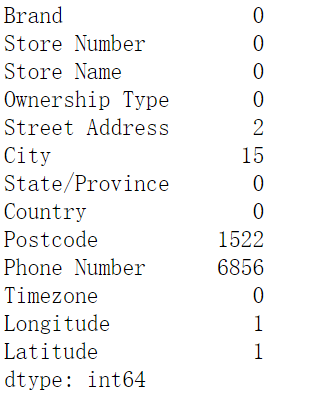
因為對city字段感興趣,所以我們查看到底缺失的數(shù)據(jù),是哪些,我們可以看出,大部分是埃及的國家(是不是這些國家沒有劃分城市,還是說沒有錄入數(shù)據(jù))。
- data[data['City'].isnull()]
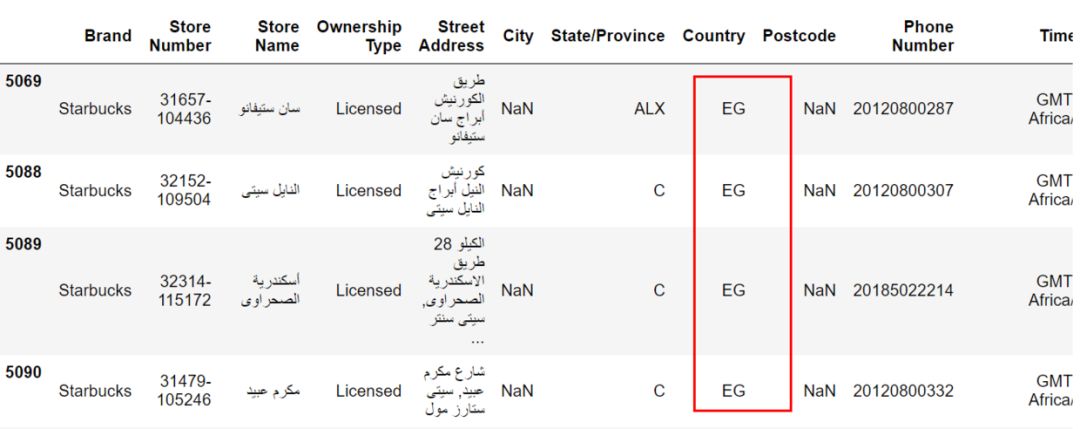
接著,我們就處理這些缺失值。缺失值一般的處理方法有兩種:
- 刪掉
- 填充
這里我們選擇就用國家字段填充到City字段上。
- def fill_na(x):
- return x
- data['City'] = data['City'].fillna(fill_na(data['State/Province']))
- data[data['Country']=='EG']
在數(shù)據(jù)分析中,我發(fā)現(xiàn)小美國的數(shù)據(jù)把臺灣當(dāng)做了國家,這我能忍么?直接重新賦值,換成了中國(中國一點(diǎn)都不能少)。整個的數(shù)據(jù)處理就到這了。
- data['Country'][data['Country'] == 'TW'] = 'CN'
分析+可視化
在python數(shù)據(jù)分析中,我常常會把分析和可視化結(jié)合在一起,首先我們看看哪些國家星巴克店最多。
通過值計數(shù),看看前10個國家。當(dāng)然,數(shù)據(jù)分析中也會有各種方法:
- 值計數(shù)
- 數(shù)據(jù)分組聚合
- 透視表
- country_count = data['Country'].value_counts()[0:10]
接著,我們就用pandas可視化(后兩期再介紹功能更強(qiáng)大的可視化方法)。可以看出:美國和中國的是最多的。
- import matplotlib.pyplot as plt
- plt.rcParams['font.sans-serif'] = ['simhei'] #指定默認(rèn)字體
- plt.rcParams['axes.unicode_minus'] = False #解決保存圖像是負(fù)號'-'顯示為方塊的問題
- %matplotlib inline
- country_count.plot(kind='bar')
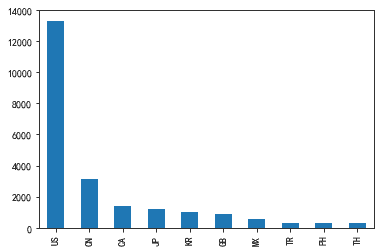
接著同樣的方法,看看哪些城市的星巴克最多?默默發(fā)現(xiàn),上海市最多(竟然不是美國城市),果然中國市場很大嘛。
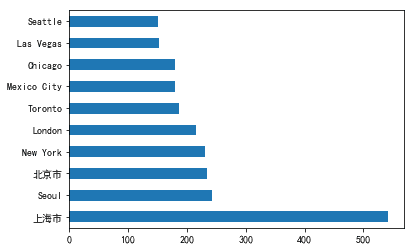
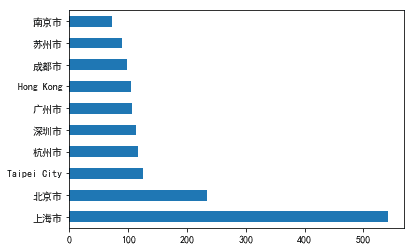
最后,篩選出中國地區(qū)的數(shù)據(jù),看看中國城市的星巴克數(shù)量排名。上海最多,北京第二,上榜的也可以看出都是經(jīng)濟(jì)較發(fā)達(dá)的城市~
- china_data = data[data['Country'] == 'CN']
- city_count = china_data['City'].value_counts()[0:10]
- city_count.plot(kind='barh')
今日互動
代碼下載:https://github.com/panluoluo/crawler-analysis,下載完整數(shù)據(jù)和代碼。
來自公眾號: 羅羅攀
以上就是關(guān)于【Python有趣|數(shù)據(jù)分析三板斧】的解答,如需了解學(xué)校/賽事/課程動態(tài),可至翰林教育官網(wǎng)獲取更多信息。
往期文章閱讀推薦:
【組隊招募】經(jīng)濟(jì)/數(shù)模競賽CNEC/IEO/SIC/HiMCM…組隊報名!


翰林AMC8視頻課重磅上線!

國際競賽真題資源免費(fèi)領(lǐng)取






