ap統(tǒng)計學(xué)難嗎,ap統(tǒng)計學(xué)怎么學(xué)?

ap統(tǒng)計學(xué)難嗎?根據(jù)數(shù)據(jù)顯示,2020年網(wǎng)考時,AP統(tǒng)計考生人數(shù)高達18萬。在AP理科中,統(tǒng)計考試占比僅次于微積分AB和生物。但是,對于AP統(tǒng)計的難度評價卻不一。有些考生認(rèn)為統(tǒng)計比微積分還難,學(xué)了半天也無法理解;而有些考生則認(rèn)為統(tǒng)計是AP中最簡單的一科,學(xué)一學(xué)就能拿到4分,稍微努力一下就能得到5分。
實際上,AP統(tǒng)計的難度與眾不同。雖然在統(tǒng)計中幾乎沒有復(fù)雜的計算,但是其中的概念卻相當(dāng)復(fù)雜,需要逐級理解。重點并不在于數(shù)學(xué)解題的邏輯思維,而是如何將這些概念應(yīng)用到實際問題中。因此,學(xué)生們需要花時間去理解和掌握統(tǒng)計中的各種概念,才能在考試中取得好成績。
抽樣 Sampling
我們常說的抽樣檢測就是AP統(tǒng)計的范圍,一個抽樣(Sampling),一個實驗(Experiment),最后進行假設(shè)檢驗(Hypothesis test),這就成功完成了一個研究。這類的基礎(chǔ)知識,是無論進行哪一個理科科目地學(xué)習(xí)都必須要具備的。所以超級重要,好好學(xué)!
簡單來說,抽樣(Sampling)就是從總體(population)中提出樣本(sample)的過程。目的就是為了省事,不用對(量大的)總體進行一個個檢測,而是通過測其中一些有代表性的樣本數(shù)據(jù)再反推總體的數(shù)據(jù)。 而最簡單的也是我們常說的抽樣方式,就是簡單隨機抽樣(Simple Random Sampling),從總體中隨機抽取樣本。那么如何做到隨機,這時統(tǒng)計就派上用場了。1. 把總體中每個個體的數(shù)字作為標(biāo)簽2. 通過計算器,隨機產(chǎn)生幾個數(shù)字3. 這些選出的數(shù)字所對應(yīng)的個體,就組成了我們所需要的樣本。
其實,就是以數(shù)字的方式代替所有的人或物,再通過數(shù)學(xué)的方法進行隨機抽取。
除了最直接的簡單隨機抽樣,還有幾種適合不同場景的抽樣調(diào)查方法。比如考試經(jīng)常出現(xiàn)的分層隨機抽樣(Stratifiedrandom sampling)和整群隨機抽樣(Cluster random sampling)。
分層隨機抽樣(Stratifiedrandom sampling)是先將總體按照一個標(biāo)準(zhǔn)分層,每層中抽取固定個數(shù)的個體,組成樣本。這種方式的適用場景是在總體分層后,每層的差距比較大,不過層內(nèi)部的個體差異不大。
比如:當(dāng)校長想要知道這個高中里學(xué)生對學(xué)校的滿意度,可以根據(jù)年級把所有學(xué)生分三層,每個年級是一層。再從每個年級的學(xué)生中都挑20個,最后一共有60人被抽出,也就是樣本。這種時候同一年級,也就是同一層的學(xué)生差距并不大,學(xué)的知識都差不多。但是高一和高三的學(xué)生比,就相差比較多。
這是我們所說的適用于分層隨機抽樣的情況。
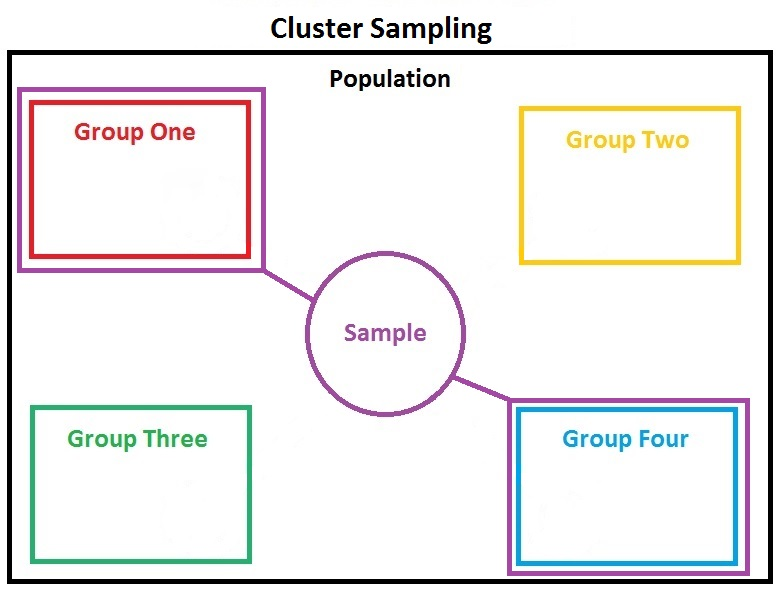
整群隨機抽樣(clusterrandom sampling)則是和分層隨機抽樣完全相反的另一種方法。是在總體分組后,隨機抽取其中一或多個組的所有個體成為樣本。這種方式適用于組和組之間差距不大,但是組內(nèi)多樣性高的情況。
比如:想要知道高三年級的同學(xué)在數(shù)學(xué)課堂上的表現(xiàn),可以先根據(jù)班,把所有學(xué)生分成不同組,一個班為一組。直接抽取其中兩個班,各做一次公開課就能得到結(jié)果。這時班和班的差距其實并不大(沒有實驗班),但是班級內(nèi)部有很喜歡聽課的同學(xué),也有很不喜歡上課的同學(xué),這會導(dǎo)致差異性比較大。
和分層隨機抽樣相比,整群隨機抽樣的操作難度一下子降低了,不用到處跑來跑去拜訪所有層,但是大多時候很難像分層隨機抽樣,保證樣本足夠多樣性。
選擇合適的抽樣方式,并且能通順不出錯地寫出來可是超級超級超級重要的!
比如,某年真題考到量森林中樹的維度:一共上百畝的森林,可以選擇整群抽樣,只隨機測幾畝森林里所有樹的維度,這樣肯定方便。但更好的方式則是在每一畝都挑幾棵樹來測維度,雖然麻煩,但是因為每一畝地的陽光,土壤資源都不一樣,這樣的方式保證了樣本和總體更加匹配。
最后還有一種隨機抽樣的方法,叫做等距抽樣(Systematic random sampling)。第一步不再是分組,而是要把總體中的所有個體按某種順序排列,抽取每次的第k個作為樣本。這種與眾不同的方法在考試中并沒有前面三種考的頻繁,但也是重點之一。
舉個例子:籃球隊選參賽人,先按照高矮個把所有人排好順序,從中抽取第三個,第六個,第九個,第十二個......作為樣本(其實就是每次的第三個)。這種方法固然可以保證樣本與總體的相似性,但也要注意避免讓排列好的總體有任何的重復(fù)。如果籃球隊員的排列方式是170,180,185,170,180,185... 有可能每次挑出來的籃球隊員都是身高180哦。
抽樣偏差 Sampling Bias
有好的抽樣方法,就肯定存在有問題的方法,也就是抽樣調(diào)查中出現(xiàn)的各種Bias。?比如從一開始就出現(xiàn)覆蓋不全的偏差(undercoverage bias)。顧名思義,undercoverage指的是抽取樣本時,并沒有在應(yīng)該的總體中抽取,而是漏掉了從一部分中的一個更小的總體中抽取。
比如電話抽樣問題:當(dāng)政府領(lǐng)導(dǎo)想要調(diào)查市民對于新政策的意向時,從電話本上隨機抽取一些人的電話詢問他們的意見。這看起來流程沒什么問題,實際上從最開始的電話本就錯了。電話本很難保證覆蓋所有市民的電話,那電話沒登記在電話本上該怎么辦呢?這些人的意見就直接被放棄了嗎?因此除非題目表示電話本上有所有人的電話,否則只要一提電話抽樣,那肯定出現(xiàn)了undercoverage bias。
電話調(diào)查不僅有覆蓋不全的偏差,同時也很容易出現(xiàn)其它兩種偏差:不回答偏差(Nonresponsebias)和回答偏差(Response bias)。?不回答偏差(Nonresponse bias)是打了電話但對方?jīng)]接,或者打通了可對方拒絕回答。只要沒得到想要的答案,都算是nonresponse bias。?與之相反的回答偏差(Response bias)指的是得到了關(guān)于問題的回答,可是對方回答的并不是心里想的,或者并不是真實情況。比如打電話問道“你是否偷過東西”,一些真正偷過東西的人可能就會因為面子說沒有。?這兩個問題并不只會在打電話時存在,如果面對面問一些敏感問題,可能更容易出現(xiàn)。不過好在兩個都有相應(yīng)的解決辦法。比如通過隨機抽取更多的人,彌補上不接電話或者不回答人數(shù)的缺口,又比如通過匿名等保護信息的方式,讓實驗對象不受面子的影響,從而愿意說真話。
實驗 vs 觀察研究?
Experiment vs. Observational study
當(dāng)抽樣完成之后,被實驗的對象也就都足夠了。那如何通過一系列的操作,從實驗對象中得到需要的數(shù)據(jù),則是我們后面研究的部分。?在日常生活中簡單又常見的方式,問卷調(diào)查(Survey),它其實并不能被稱為一個實驗,因為它只能被叫做一種觀察研究(Observational study)。這類觀察研究的特點,就是不對實驗對象做出任何的改變。
比如:想要研究文化水平與收入之間的關(guān)系,通過問卷調(diào)查100人的文化水平與收入,得出結(jié)論。此時研究對象并沒有被動的文化水平低或者高,也沒有被動地掙得更多或者更少。
研究人員發(fā)了問卷,只起到了觀察的作用,并沒有進行實質(zhì)性的改變,這種就是觀察研究。 那什么才是一個真正的實驗(Experiment)呢?答案有改變的實驗叫做真正的實驗。
舉個例子:想要研究司機聽不同音量的音樂和反應(yīng)速度的關(guān)系,可以通過讓同一個司機聽兩次不同大小音量的音樂,再測試反應(yīng)速度進行對比。這時讓司機聽音樂的操作就是對他們進行的改變,也就是treatment。
是否有改變,直接影響了研究的類型,更重要的是影響了結(jié)果。觀察研究因為無法確認(rèn)誰導(dǎo)致誰,因此只能得出正相關(guān)與負(fù)相關(guān)。
如果研究結(jié)果是文化水平和收入呈正相關(guān),也無法判定是因為文化水平高導(dǎo)致收入高,還是收入高所以有更好的教育資源,所以文化水平高。但是因為實驗是進行了改變的,所以可以得到我們更希望的因果關(guān)系結(jié)論。
實驗 Experiment
在AP統(tǒng)計考試中,研究比較多的是實驗,因此就涉及到了實驗的方法。?我們最簡單常見的方法就是完全隨機設(shè)計(Completely randomized design),將每一個實驗對象都隨機分配至實驗組或?qū)φ战M,最后把兩組的數(shù)據(jù)進行對比。通常實驗組是對實驗對象進行改變,而對照組則是不進行改變。但有時因為實驗比較復(fù)雜,實驗組會有好幾個,那么就要把實驗對象隨機分配到幾個組中的一個,再進行對比。
稍微復(fù)雜一點的實驗方法叫做隨機區(qū)組設(shè)計(Randomized block design)。先根據(jù)某個標(biāo)準(zhǔn)把樣本分為兩組,再把每組的人分別隨機分到實驗組和對照組。
比如:研究人在不同商場中的消費金額,可以先把整體樣本分為男女兩組,再把每個男的隨機分到兩個不同的商場,女的也隨機分到兩個不同商場。這樣不僅得到了兩個商場的不同消費數(shù)據(jù),還能將男女?dāng)?shù)據(jù)進行對比。
最后一個,也是最復(fù)雜的——配對實驗(Matched-pairs design)。最簡單的解釋是,實驗組與對照組的數(shù)據(jù)可以因為實驗對象的原因一一對應(yīng)起來。 其中一種情況,是讓實驗對象每個人做兩件事。就比如之前講到的讓司機聽兩個不同音量的音樂,測反應(yīng)速度。或者測學(xué)生入學(xué)前成績和入學(xué)后成績,得出上課有沒有用的結(jié)論。這種一人做兩件事的實驗,是因一個人給出的兩個數(shù)據(jù)一定是有聯(lián)系的,但又不能把A的第一個數(shù)據(jù)和B的第二個數(shù)據(jù)聯(lián)系起來,所以數(shù)據(jù)必須一一對應(yīng)。 還有另一種情況,雖然不是同一個人做的,但是實驗對象還是兩兩一對,得出的數(shù)據(jù)也是兩兩一對不能拆開,而且是matched-pairs的情況。比如研究情侶的消費水平,雙胞胎誰會更高等等。他們往往有個不可分割的關(guān)系,也使得他們的數(shù)據(jù)牢牢綁定在一起。
寫在最后
抽樣檢測不僅是統(tǒng)計中非常重要的一部分,在其它AP科目中往往也占據(jù)一席之地。因為統(tǒng)計本身就是多個學(xué)科的基礎(chǔ),連題目都涵蓋了各個領(lǐng)域。AP統(tǒng)計作為一門基礎(chǔ)學(xué)科,其難度在AP中并不能排上一二,若你感到難以應(yīng)付,那你可能暫時還沒有找到攻破它的套路。
免費領(lǐng)取AP統(tǒng)計學(xué)資料
暑期即將來臨,提前占位國際課程輔導(dǎo)


國際競賽真題資源免費領(lǐng)取


美高學(xué)分項目重磅來襲!立即了解






